
照片真实感Avatar是远程社交的重要组成环节,系AR/VR的关键应用之一。实际上,如果你有关注映维网的分享,你会注意到Meta一直在积极探索相关的解决方案。在名为《Dressing Avatars: Deep Photorealistic Appearance for Physically Simulated Clothing》的论文中,由Meta、卡内基梅隆大学和明尼苏达大学组成的团队又针对穿衣Avatar建模提出了相关的思考方案。
尽管关于全身Avatar的研究已经产生了能够从稀疏信号中生成人类照片真实感合成表示的可动画模型,但合成真实感服饰依然是Avatar建模中的一个挑战。
同时,服饰是一种基本的自我表达形式,而创造出高品质的穿衣真实感动画的根本需要。关于可动画穿衣Avatar的现有研究主要可以分为两大类:1. 服饰模拟通过动力学创建逼真的服饰变形,但只关注几何建模;2. 另一项研究则利用真实世界捕捉来构建服饰几何的神经表示。然而,相关系统通常会阻碍服饰的动态性,难以泛化到看不见的姿态,并且无法很好地处理碰撞。
Meta团队的主要见解是,这两条路线实际上是相辅相成,可以将它们结合起来并利用两者的优势。在研究中,研究人员建议将基于物理的服饰模拟集成到Avatar建模中,以便Avatar的服饰可以与身体一起进行照片真实感的动画化,同时实现高质量的动力学、碰撞处理、以及使用新服饰对Avatar进行动画制作和渲染的能力。
值得一提的是,这项研究是以全身Codec Avatars作为基础,利用Variational Autoencoder(VAE)来模拟人体的几何结构和外观。特别是,他们遵循多层公式,但重新设计了服饰层,从而集成基于物理的模拟器。
在训练阶段,团队通过动态服饰配准管道处理原始捕获,使用真实世界的数据学习服饰外观模型。在测试时,使用适当的材质参数模拟底层身体模型之上的服饰几何,然后应用学习的外观模型合成最终输出。
遗憾的是,这个管道的简单实现存在两个主要问题。首先,模拟器输出和从实际数据获得的追踪之间存在差距。尽管在受控设置或仅在估计身体参数方面取得了一定的进展,但估计身体和服饰的全套物理参数以忠实地再现穿衣身体配置依然是一个尚未解决的问题。手动选择参数的测试时间模拟输出与用于训练的真实服饰几何图形之间存在不可避免的差异。
其次,高精度追踪服饰和潜在的身体几何形状依然是一个十分具有挑战性的问题,特别是对于宽松的服饰,如裙子和连衣裙。
这两个问题,训练和测试场景之间的不一致性,以及不可靠的追踪,使得学习一个可泛化的外观模型更具挑战性。
为此,研究人员根据架构和输入表示设计了本地化模型。他们同时从基于物理的渲染中获得灵感,将外观分解为局部漫反射组件、依赖视图和全局照明效果,如阴影。
特别是,团队依赖于一个无监督的阴影网络,以从身体和服饰几何显式计算的环境遮挡贴图为条件。因此,即使在测试时针对不同的基础身体模型,其都可以有效地建模动态阴影。所述方法可以生成物理真实的动力学和照片真实感外观,支持复杂身体-服饰交互中的各种身体运动。
另外,相关公式允许在不同个人的Avatar之间转移服饰。团队指出,这一方法为照片级真实感Avatar穿着新衣开辟了可能性。
方法介绍
研究人员的目标是构建具有动态服饰和照片级真实感外观的姿势驱动型全身Avatar。他们对Avatar进行了多视角拍摄序列的训练,每个主体都穿着感兴趣的服饰。在测试时,Avatar由骨架运动的稀疏驱动信号设置动画,并可以在新的camera视点中渲染。团队的目标是实现高保真动画,无论是从人类主体的外观还是从时间的服饰动态来看都足够逼真。
为此,他们开发了一个由三个模块组成的动画管道:底层身体Avatar模型、基于物理的服饰模拟和、以及服饰外观模型。
底层身体Avatar将骨架姿势作为输入,并输出身体几何体。给定一系列身体几何图形,然后使用服饰模拟生成具有自然和丰富动力学的服饰几何图形,并与底层身体的运动在物理上保持一致。
最后,将服饰外观模型应用于模拟几何体并生成照片级真实感纹理。其中,所述纹理不仅考虑了服饰几何体,同时考虑了Avatar身体遮挡造成的阴影。服饰投射在身体上的阴影在底层身体Avatar中进行了类似建模。图2显示了整体管道。
团队发现,服饰的高效照片级外观建模是这样一个管道中缺少的关键组件。为了构建这样一个系统,他们解决了两个主要的技术挑战。一方面,他们开发了一个深度服饰外观模型,它可以有效生成具有动态视相关和阴影效果的高度真实感服饰纹理。对于模型的设计,研究人员侧重于生成外观的泛化,因为来自服饰模拟器的输入几何体可能不同于用于训练外观模型的追踪服饰几何。
另一方面,为了生成外观模型的训练数据,他们扩展了以前的服饰配准算法,从而处理高度动态的服饰类型,包括裙子和连衣裙。另外,研究人员通过匹配显著特征来追踪服饰上的光度对应关系(所述特征对于高纹理服饰外观的建模至关重要)。
穿衣身体配准
由于服饰配准不是这项研究的核心贡献,所以他们重点关注大型服饰动态和丰富纹理带来的挑战,因为这是实现高保真动画必须解决的问题。数据采集设置与之前的工作类似。这一管道以对象的多视图图像序列作为输入,并在两个单独的层中输出服饰和底层身体的配准网格。
研究人员将原始几何体重建和网格分割到身体和服饰区域。他们同样估计了运动身体姿态和内层身体表面。
动态服饰配准的目标是以一致的对应关系在单个网格拓扑中表示服饰几何体。团队的服饰配准方法包括两个主要步骤,几何配准和光度校准。图3说明了服饰配准方法的概述。
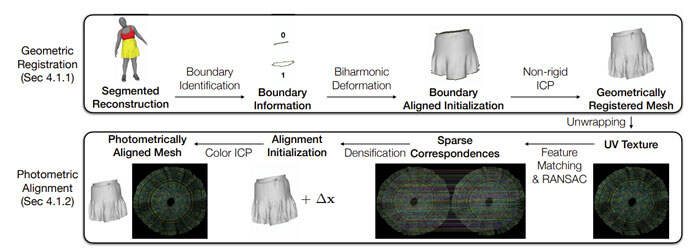
几何配准
在这一步中,使用非刚性Iterative Closest Point(ICP)算法将服饰模板拟合到重建网格的分段服饰区域。非刚性ICP算法类似于之前的研究,因此团队省略了相关细节。为了追踪宽松和动态服饰类型(如裙子和连衣裙),为非刚性ICP提供良好的初始化非常重要。
他们观察到,服饰边界提供了关于服饰整体方向和变形的有用信息。因此,他们首先估计粗糙边界对应。利用每件服饰都有固定数量的边界这一事实,通过查询追踪的内身体表面中最近的顶点,将目标服饰边界上的每个点与模板网格边界相关联。考虑到这种粗糙的边界对应关系,他们使用Biharmonic Deformation Fields来求解满足边界对齐约束的逐顶点变形,同时最小化内部变形。
研究人员使用Biharmonic Deformation Fields的输出作为非刚性ICP算法的初始化。
光度校准
几何配准方法通过最小化表面距离将衣服饰几何与单个模板拓扑对齐,但没有明确求解内部对应。为了有效地建模服饰外观,有必要确保模板中的每个顶点始终跟踪相同的颜色(基本上是反射比),这称为光度对应。他们观察到,基于chunk的逆绘制算法可以纠正几何配准步骤中光度对应的小偏差,但无法从初始化中的大误差中恢复。
在这里,他们通过匹配服饰高纹理区域中的显著特征来明确解决光度对应问题。对于序列中的每一帧,首先使用上一步中几何对齐的网格将多视图图像中的平均纹理展开到UV空间。然后,使用DeepMatching在展开纹理和模板纹理之间建立稀疏对应对。团队同时使用RANSAC来删除错误的通信。
然后,通过求解拉普拉斯方程,将稀疏对应加密到每个顶点,类似于上一步中的Biharmonic Deformation Fields。最后,在模板和目标网格之间运行彩色ICP以测光对齐所有顶点。
深度动态服饰外观模型
服饰外观模型是实现照片级真实感服饰动画系统的关键技术组件。给定服饰几何体作为输入,服饰外观模型的目标是生成可与输入几何体一起用于光栅化的服饰纹理,以生成照片级真实感外观。
他们构建了一个数据驱动的服饰外观模型,以便从实际捕获的图像序列中学习复杂的照片级真实感外观。在设计这种模型时,需要考虑几个因素。
首先,外观模型根据前一个配准步骤中的跟踪几何体进行训练,但在测试时,它将模拟服饰几何体作为输入。因此,模型必须弥合训练数据和测试数据之间的泛化差距。
其次,生成的纹理应包括照片级真实感外观的各个方面,例如视相关效果和动态阴影。
第三,为了提高效率,模型应该只涉及可以从服饰几何体中轻松推导出的基本量,而不需要计算成本高昂的操作,例如多反弹蒙特卡罗光线追踪。
研究人员从捕获设置中获得了一系列配准的服饰网格{























 产品与服务
产品与服务
 联系站长
联系站长
 关于我们
关于我们